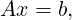
This section of the file defines parameters and boundary conditions which define the nature of
the problem to be solved. These are enclosed in the CONDITIONS tag.
Numerical parameters may be required by a particular solver (for instance time-integration or
physical parameters), or may be arbitrary and only used for the purpose of simplifying the
problem specification in the session file (e.g. parameters which would otherwise be repeated in
the definition of an initial condition and boundary conditions). All parameters are enclosed in
the PARAMETERS XML element.
A parameter may be of integer or real type and may reference other parameters defined previous to it. It is expressed in the file as
For example,
A number of pre-defined constants may also be used in parameter expressions, for example PI.
A full list of supported constants is provided in Section 3.7.1.2.
These specify properties to define the parameters specific to the time integration scheme to be used. The parameters are specified as XML elements and require a string corresponding to the time-stepping method and the order, and optionally the variant and free parameters. For example,
For additional details on the different time integration schemes refer to the developer’s guide.
These specify properties to define the actions specific to solvers, typically including the equation to solve and the projection type. The property/value pairs are specified as XML attributes. For example,
Boolean-valued solver properties are specified using True or False. The list of available solvers
in Nektar++ can be found in Part III.
Drivers are defined under the CONDITIONS section as properties of the SOLVERINFO
XML element. The role of a driver is to manage the solver execution from an upper
level.
The default driver is called Standard and executes the following steps:
SolverType in the SOLVERINFO XML element.
In the following example, the driver Standard is used to manage the execution of the
incompressible Navier-Stokes equations:
If no driver is specified in the session file, the driver Standard is called by default. Other
drivers can be used and are typically focused on specific applications. As described in Sec.
11.3.1 and 11.4.1, the other possibilities are:
ModifiedArnoldi - computes of the leading eigenvalues and eigenmodes using
modified Arnoldi method.
Arpack - computes of eigenvalues/eigenmodes using Implicitly Restarted Arnoldi
Method (ARPACK).
SteadyState - uses the Selective Frequency Damping method (see Sec. 11.1.5)
to obtain a steady-state solution of the Navier-Stokes equations (compressible or
incompressible).
These define the number (and name) of solution variables. Each variable is prescribed a unique ID. For example a two-dimensional flow simulation may define the velocity variables using
Many Nektar++ solvers use an implicit formulation of their equations to, for instance, improve timestep restrictions. This means that a large matrix system must be constructed and a global system set up to solve for the unknown coefficients. There are several approaches in the spectral/hp element method that can be used in order to improve efficiency in these methods, as well as considerations as to whether the simulation is run in parallel or serial. Nektar++ opts for ‘sensible’ default choices, but these may or may not be optimal depending on the problem under consideration.
This section of the XML file therefore allows the user to specify the global system solution parameters, which dictates the type of solver to be used for any implicit systems that are constructed. This section is particularly useful when using a multi-variable solver such as the incompressible Navier-Stokes solver, as it allows us to select different preconditioning and residual convergence options for each variable. As an example, consider the block defined by:
The above section specifies that the variables u,v,w should use the IterativeStaticCond
global solver alongside the LowEnergyBlock preconditioner and an iterative tolerance of 10-8
on the residuals. However the pressure variable p is generally stiffer: we therefore opt for a
more expensive FullLinearSpaceWithLowEnergyBlock preconditioner and a larger residual of
10-6. We now outline the choices that one can use for each of these parameters and give a
brief description of what they mean.
Defaults for all fields can be defined by setting the equivalent property in the SOLVERINFO
section. Parameters defined in this section will override any options specified there.
GlobalSysSoln optionsNektar++ presently implements four methods of solving a global system:
NEKTAR_USE_MPI option is enabled in the CMake configuration.
NEKTAR_USE_PETSC
option is enabled in the CMake configuration.These solvers can be run in one of three approaches:
The GlobalSysSoln option is formed by combining the method of solution with the approach:
for example IterativeStaticCond or PETScMultiLevelStaticCond.
Preconditioners can be used in the iterative and PETSc solvers to reduce the number of iterations needed to converge to the solution. There are a number of preconditioner choices, the default being a simple Jacobi (or diagonal) preconditioner, which is enabled by default. There are a number of choices that can be enabled through this parameter, which are all generally discretisation and dimension-dependent:
| Name | Dimensions | Discretisations |
Null | All | All |
Diagonal | All | All |
FullLinearSpace | 2/3D | CG |
LowEnergyBlock | 3D | CG |
Block | 2/3D | All |
FullLinearSpaceWithDiagonal | All | CG |
FullLinearSpaceWithLowEnergyBlock | 2/3D | CG |
FullLinearSpaceWithBlock | 2/3D | CG |
For a detailed discussion of the mathematical formulation of these options, see the developer guide.
The SuccessiveRHS option can be used in the iterative solver only, to attempt to reduce the
number of iterations taken to converge to a solution. It stores a number of previous solutions
or right-hand sides, dictated by the setting of the SuccessiveRHS option, to give a better
initial guess for the iterative process. This method is better than any linear extrapolation
method.
It can be activated by setting
or
The typical value of SuccessiveRHS is ≤10.
The linear problem to be solved is
|
| (3.1) |
here x and b are both column vectors. There are a sequence of already solved linear problems
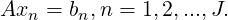 | (3.2) |
Assume xn are all linearly independent. In the successive right-hand method (see [13]), the best approximation to x is
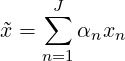 | (3.3) |
which is found by minimizing the object function
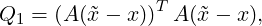 | (3.4) |
or
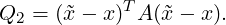 | (3.5) |
If Q1 is used, the projection bases are em = bm,m = 1,2,...,J. Using
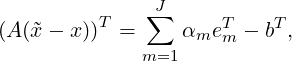 | (3.6) |
there is
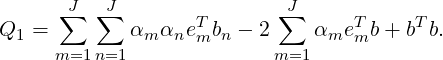 | (3.7) |
To minimize Q1, there should be ∂Q1∕∂αm = 0,m = 1,2,...,J. The corresponding linear problem is
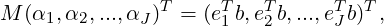 | (3.8) |
with symmetric positive definite coefficient matrix Mmn = emT bn. In this case, both the solutions xm and the right-hand sides bm need to be stored.
If Q2 is used, A should be a symmetric positive definite matrix, as those encountered in the Poisson equation and the Helmholtz equation. Here, the projection bases are êm = xm,m = 1,2,...,J. Using
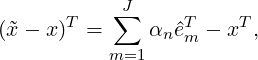 | (3.9) |
there is
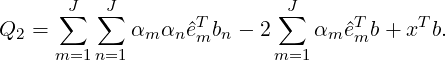 | (3.10) |
To minimize Q2, there should be ∂Q2∕∂αm = 0,m = 1,2,...,J. The corresponding linear problem is
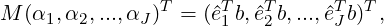 | (3.11) |
with symmetric positive definite coefficient matrix Mmn = êmT bn. In this case, only the solutions xm need to be stored.
The formulations of Q1 version and Q2 version are the same, except the difference of
projection bases. By default, Q2 is used as the object function. If you want to use Q1 instead,
you can assign a negative value to SuccessiveRHS:
or
In the original paper of Fischer (1998) [13], the Gram-Schmidt orthogonal process is applied to the projection bases, this method is very stable and avoids the calculation of M-1. However, when the memory space is full, this approach makes it hard to decide which basis should be overwritten. In our implementation, we just store the normalized right-hand sides or old solutions, i.e. emT bm = 1 or êmT bm = 1, and overwrite the oldest ones. The linear problem (3.8) or (3.11) is solved using a direct method.
To make sure M is positive definite, when a new basis eJ+1 arrives, we test the following condition to decide whether or not to accept it,
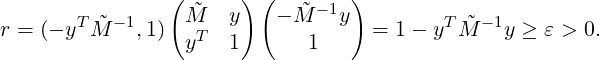 | (3.12) |
Assuming eJ is the oldest basis, there are 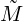 mn = Mmn,ym = emT bJ+1,(m,n = 1,2,...,J - 1).
mn = Mmn,ym = emT bJ+1,(m,n = 1,2,...,J - 1).
The PETSc solvers, although currently experimental, are operational both in serial and parallel. PETSc gives access to a wide range of alternative solver options such as GMRES, as well as any packages that PETSc can link against, such as the direct multi-frontal solver MUMPS.
Configuration of PETSc options using its command-line interface dictates what matrix
storage, solver type and preconditioner should be used. This should be specified in a .petscrc
file inside your working directory, as command line options are not currently passed through to
PETSc to avoid conflict with Nektar++ options. As an example, to select a GMRES solver
using an algebraic multigrid preconditioner, and view the residual convergence, one can use
the configuration:
Or to use MUMPS, one could use the options:
A final choice that can be specified is whether to use a shell approach. By default, Nektar++
will construct a PETSc sparse matrix (or whatever matrix is specified on the command line).
This may, however, prove suboptimal for higher order discretisations. In this case, you may
choose to use the Nektar++ matrix-vector operators, which by default use an assembly
approach that can prove faster, by setting the PETScMatMult SOLVERINFO option to
Shell:
The downside to this approach is that you are now constrained to using one of the Nektar++ preconditioners. However, this does give access to a wider range of Krylov methods than are available inside Nektar++ for more advanced users.
Boundary conditions are defined by two XML elements. The first defines the boundary regions
in the domain in terms of composite entities from the GEOMETRY section of the file. Each
boundary region has a unique ID and are defined as,
For example,
The boundary regions can also optionally contain a name which is then used in the multi-block VTK output to label the block descriptively rather than by ID, for example
The second XML element defines, for each variable, the condition to impose on each boundary region, and has the form,
There should be precisely one REGION entry for each B entry defined in the BOUNDARYREGION
section above. For example, to impose a Dirichlet condition on both variables for a domain
with a single region,
Boundary condition specifications may refer to any parameters defined in the session file. The
REF attribute corresponds to a defined boundary region. The tag used for each variable
specifies the type of boundary condition to enforce.
Dirichlet conditions are specified with the D tag.
| Projection | Homogeneous support | Time-dependent support | Dimensions |
| CG | Yes | Yes | 1D, 2D and 3D |
| DG | Yes | Yes | 1D, 2D and 3D |
| HDG | Yes | Yes | 1D, 2D and 3D |
Example:
Neumann conditions are specified with the N tag.
| Projection | Homogeneous support | Time-dependent support | Dimensions |
| CG | Yes | Yes | 1D, 2D and 3D |
| DG | No | No | 1D, 2D and 3D |
| HDG | ? | ? | ? |
Example:
Periodic conditions are specified with the P tag.
| Projection | Homogeneous support | Dimensions |
| CG | Yes | 1D, 2D and 3D |
| DG | No | 2D and 3D |
Example:
Periodic boundary conditions are specified in a significantly different form to other conditions.
The VALUE property is used to specify which BOUNDARYREGION is periodic with the current
region in square brackets.
Caveats:
Time-dependent boundary conditions may be specified through setting the USERDEFINEDTYPE
attribute and using the parameter t where the current time is required. For example,
Boundary conditions can also be loaded from file. The following example is from the Incompressible Navier-Stokes solver,
Boundary conditions can also be loaded simultaneously from a file and from an expression (currently only implemented in 3D). For example, in the scenario where a spatial boundary condition is read from a file, but needs to be modulated by a time-dependent expression:
In the case where both VALUE and FILE are specified, the values are multiplied together to give
the final value for the boundary condition.
Finally, multi-variable functions such as initial conditions and analytic solutions may
be specified for use in, or comparison with, simulations. These may be specified
using expressions (<E>) or imported from a file (<F>) using the Nektar++ FLD file
format
A restart file is a solution file (in other words an .fld renamed as .rst) where the field data is specified. The expansion order used to generate the .rst file must be the same as that for the simulation. .pts files contain scattered point data which needs to be interpolated to the field. For further information on the file format and the different interpolation schemes, see section 5.6.20. All filenames must be specified relative to the location of the .xml file.
With the additional argument TIMEDEPENDENT="1", different files can be loaded for each
timestep. The filenames are defined using boost::format syntax where the step time is used as
variable. For example, the function Baseflow would load the files U0V0_1.00000000E-05.fld,
U0V0_2.00000000E-05.fld and so on.
For .pts files, the time consuming computation of interpolation weights is only performed for the first timestep. The weights are stored and reused in all subsequent steps, which is why all consecutive .pts files must use the same ordering, number and location of data points.
Other examples of this input feature can be the insertion of a forcing term,
or of a linear advection term
Note that it is sometimes the case that the variables being used in the solver do not
match those saved in the FLD file. For example, if one runs a three-dimensional
incompressible Navier-Stokes simulation, this produces an FLD file with the variables u, v, w
and p. If we wanted to use this velocity field as input for an advection velocity, the
advection-diffusion-reaction solver expects the variables Vx, Vy and Vz. We can manually
specify this mapping by adding a colon to the filename, indicating the variable names in the
target file that align with the desired function variable names. This gives a definition such
as:
There are some caveats with this syntax:
VAR attribute and in the
comma-separated list after the colon. For example, the following is not valid:
*, so one cannot write for example:
With the additional argument TIMEDEPENDENT="1", different files can be loaded for each
timestep. The filenames are defined using boost::format syntax where the step time is used as
variable. For example, the function Baseflow would load the files U0V0_1.00000000E-05.fld,
U0V0_2.00000000E-05.fld and so on.
Section 3.7 provides the list of acceptable mathematical functions and other related technical details.
To generate a Quasi-3D appraoch with Nektar++ we only need to create a 2D or a 1D mesh, as reported above, and then specify the parameters to extend the problem to a 3D case. For a 2D spectral/hp element problem, we have a 2D mesh and along with the parameters we need to define the problem (i.e. equation type, boundary conditions, etc.). The only thing we need to do, to extend it to a Quasi-3D approach, is to specify some additional parameters which characterise the harmonic expansion in the third direction. First we need to specify in the solver information section that that the problem will be extended to have one homogeneouns dimension; here an example
then we need to specify the parameters which define the 1D harmonic expanson along the
z-axis, namely the homogeneous length (LZ) and the number of modes in the homogeneous
direction (HomModesZ). HomModesZ corresponds also to the number of quadrature points in
the homogenous direction, hence on the number of 2D planes discretized with a spectral/hp
element method.
In case we want to create a Quasi-3D approach starting from a 1D spectral/hp element mesh, the procedure is the same, but we need to specify the parameters for two harmonic directions (in Y and Z direction). For Example,
By default the operations associated with the harmonic expansions are performed with the Matrix-Vector-Multiplication (MVM) defined inside the code. The Fast Fourier Transform (FFT) can be used to speed up the operations (if the FFTW library has been compiled in ThirdParty, see the compilation instructions). To use the FFT routines we need just to insert a flag in the solver information as below:
The number of homogeneous modes has to be even. The Quasi-3D approach can be created starting from a 2D mesh and adding one homogenous expansion or starting form a 1D mesh and adding two homogeneous expansions. Not other options available. In case of a 1D homogeneous extension, the homogeneous direction will be the z-axis. In case of a 2D homogeneous extension, the homogeneous directions will be the y-axis and the z-axis.